3. cuda programming
待处理
cuda mma/wgmma 矩阵乘的实现和优化
3.1. MMA (Matrix Multiply-Accumulate Instructions)
Tensor core 的操作的基础形状如下:

3.2. old
3.2.1. Occupancy
Occupancy is the ratio of the number of active warps per multiprocessor to the maximum number of possible active warps.
3.2.2. floating point number
3.2.2.1. BFLOAT16
bfloat16 does not support subnormal number.
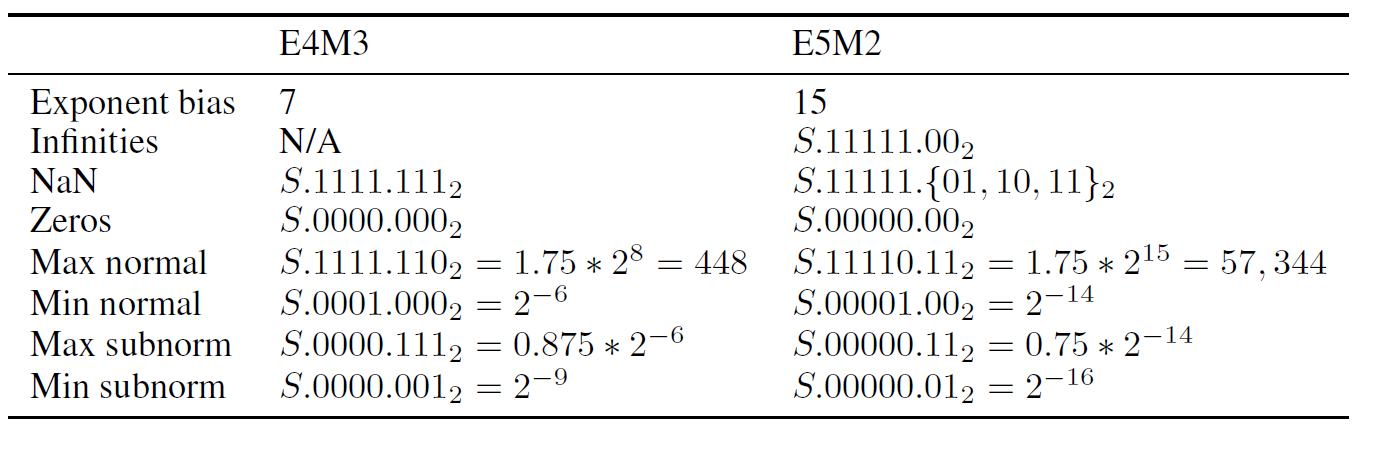
3.2.2.2. FP8
The 8-bit floating point (FP8) binary interchange format consisting of two encodings:
E4M3 : 4-bit exponent and 3-bit mantissa
E5M2 : 5-bit exponent and 2-bit mantissa
E5M2 follows IEEE 754 conventions for representatio of special values. But E4M3’s dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs.
E5M2格式遵守IEEE-754规范,但E4M3格式不遵守IEEE-754规范。E4M3没有无穷大且除符号位外全为1表示NaN。
3.3. cuda environment
CUDA 11.0 adds support for the NVIDIA Ampere GPU microarchitecture (compute_80 and sm_80),
and supports bf16 data type (__nv_bfloat16) and compute type TF32 (tf32).
CUDA 11.1 adds support for NVIDIA Ampere GPU architecture based GA10x GPUs GPUs (compute capability 8.6), including the GeForce RTX-30 series.
CUDA 11.5:
linking is supported with cubins larger than 2 GB.
include cub.
CUDA 11.8:
This release introduces support for both the Hopper and Ada Lovelace GPU families.
Added fp8 data types and type conversion functions support via the new header cuda_fp8.h.
Performance improvements in bfloat16 basic arithmetic header for sm_90 targets.
3.4. whitepaper
3.4.1. A100
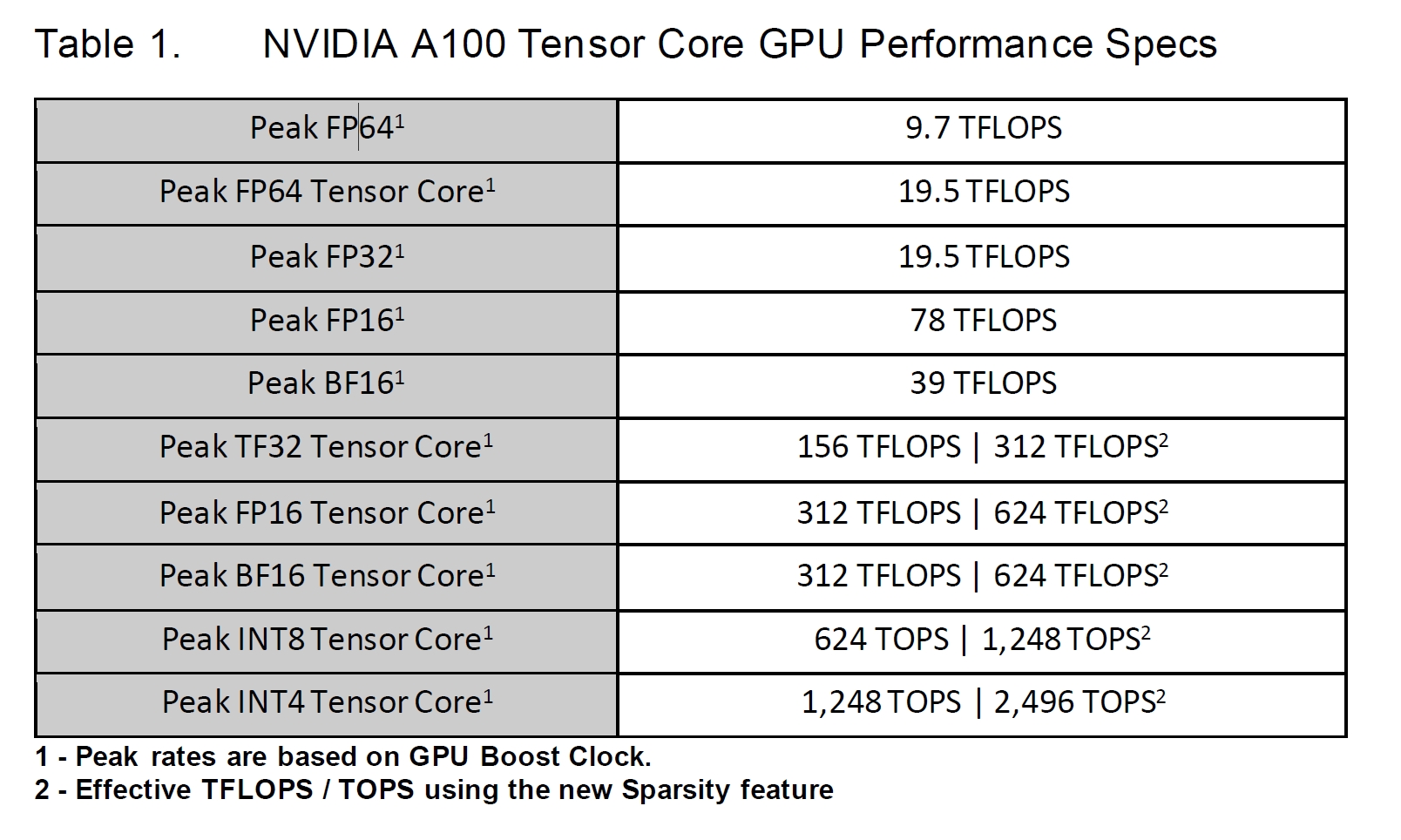
1555 GB/sec of memory bandwidth